The Rise of Ollama: Democratizing the Frontier of Local Intelligence
Ollama makes it easy to run local LLM on your computer without hassles.
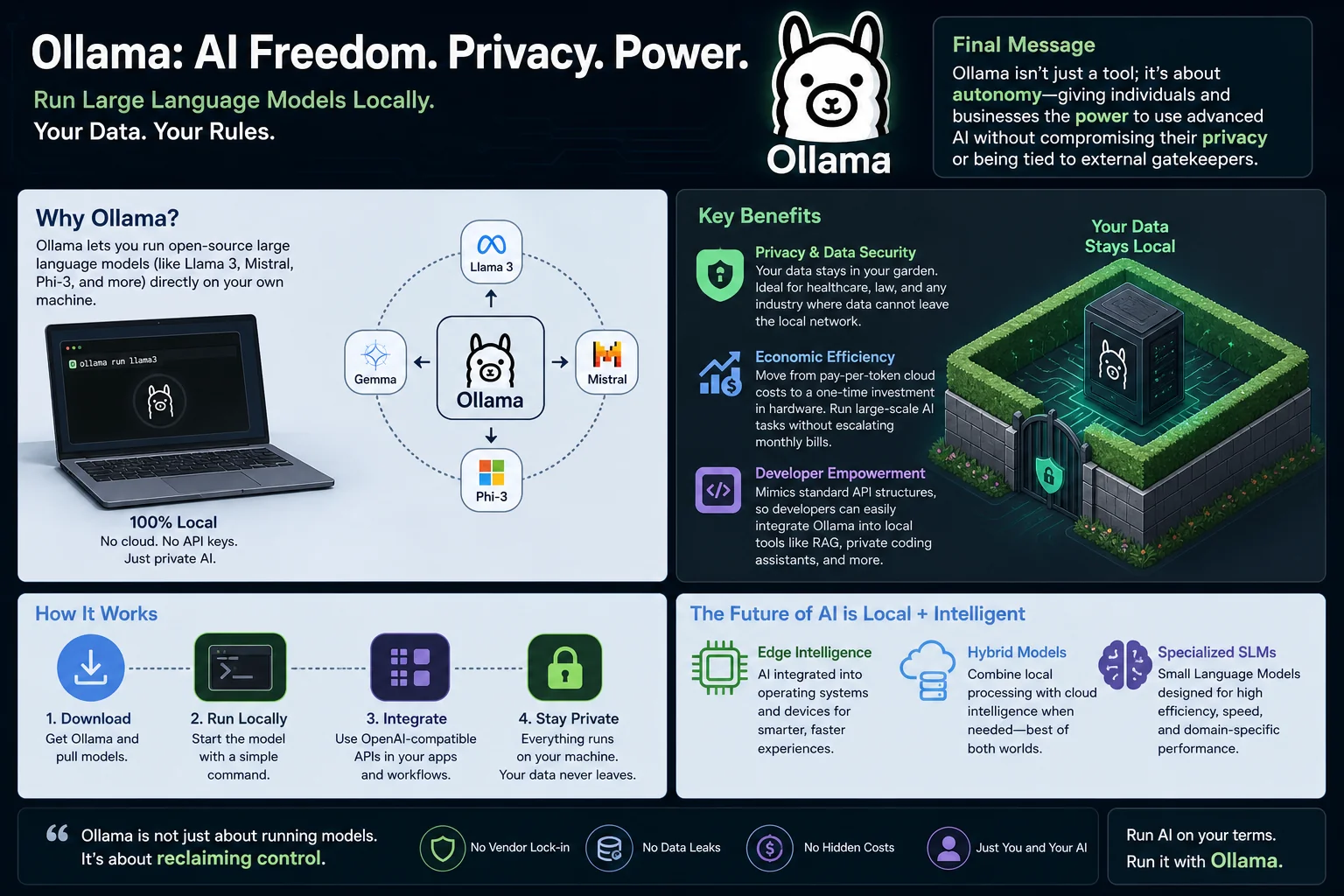
Two years ago, running an AI model on your own laptop was a weekend project for specialists. Today, it takes one command. That shift has a name: Ollama.
This isn't just a developer story. It's about a fundamental tension playing out across every industry — convenience versus control — and why millions of people are choosing to keep their AI local.
The Problem With "Send It to the Cloud"
When you use ChatGPT, Claude, or most major AI tools, here's what actually happens: your data leaves your device, travels to a remote data center, gets processed by GPU clusters you don't own, and returns to you. For most tasks, that's fine. But for a lawyer reviewing confidential documents, a doctor analyzing patient notes, or a developer working on proprietary code, that's a dealbreaker.
The numbers back this up. Enterprise AI teams are increasingly reluctant to route sensitive data through public clouds — a recent industry poll found the share of organizations weighing on-premises AI equally with cloud grew from 37% in 2024 to 45% in 2025. That's a fast-moving shift. Another theCUBE research analysis found enterprises are now nearly split 50/50 between cloud and on-premises environments for new generative AI applications — a striking change from just a few years ago when cloud was the assumed default.
Ollama is the primary reason on-premises AI is now a realistic option for most teams.
What Ollama Actually Does
At its core, Ollama is an open-source runtime that lets you run large language models (LLMs) directly on your own hardware — laptop, workstation, or internal server.
Before Ollama, doing this required managing Python environments, configuring GPU drivers, and wrestling with various model formats (GGUF, EXL2, and others). It was a multi-hour setup that kept most developers out. Ollama reduced that to a single command:
ollama run llama3
It handles the model weights, optimizes hardware utilization, and exposes a local REST API that mimics OpenAI's structure. That last part is important: it means developers can swap a cloud API key for a local Ollama endpoint with minimal code changes. The barrier to trying local AI dropped from "afternoon project" to "five minutes."
The traction reflects that simplicity. As of mid-2026, Ollama's GitHub repository has crossed 174,000 stars — placing it among the most-starred open-source AI projects in existence — with over 52 million monthly downloads and 578 releases (averaging roughly one every two days). It now supports over 135,000 GGUF models from HuggingFace, and integrates with tools like Claude Code, GitHub Copilot CLI, and Cursor.
Four Reasons It Took Off
1. It actually works on hardware people own
Earlier local AI efforts required expensive, specialized rigs. Ollama's mastery of quantization changed that. Quantization compresses model weights — a technique that lets a 12-billion parameter model fit into a fraction of its original memory footprint. In practice, this means a developer with a single mid-range GPU can run a capable model that would otherwise require a server rack.
In 2026, Ollama supports INT4 and INT2 quantization, the current frontier of compression. Real-world benchmark data shows the impact: Qwen2.5-Coder 32B running locally via Ollama scores 92.7% on HumanEval — higher than GPT-4's 87.1% — on a 24GB GPU.
2. Data never leaves the building
For regulated industries, this isn't a nice-to-have. When a company runs Ollama on an internal server, data doesn't cross the firewall. The AI works with your context without any of it reaching the public internet. Legal firms, healthcare providers, and financial institutions are increasingly treating this as a prerequisite for AI adoption rather than a luxury.
3. The economics shift from monthly bills to one-time hardware
Cloud LLM costs scale with usage. For high-volume applications — an internal chatbot, an automated coding assistant, a document summarization pipeline — per-token pricing adds up fast, often into thousands of dollars per month.
Ollama lets organizations move from an operating expense (pay forever per token) to a capital expense (buy hardware once, generate tokens indefinitely). The ongoing cost becomes electricity. For teams running millions of tokens a month, this is a meaningful financial difference.
4. It's where the developer ecosystem lives
Because Ollama mirrors the OpenAI API structure, the tooling ecosystem built around it is enormous. Developers are using it to build:
- Local coding assistants that read your entire repository without uploading your source code anywhere
- RAG (Retrieval-Augmented Generation) systems where a chatbot reads company documentation and answers questions — entirely on your internal network
- Automated content pipelines that process documents in batches without hitting rate limits or incurring API costs
A global deployment survey of over 174,500 Ollama instances found the most popular model configuration is Llama 3 at 8B parameters with 4-bit quantization — a setup that balances capability and hardware accessibility for most users.
Where Ollama Is Headed
Hybrid intelligence, not a binary choice
The framing of "local vs. cloud" is already becoming outdated. The practical future is hybrid: a local Ollama-powered model handles routine tasks (summarization, formatting, classification), while a heavyweight cloud model is called only when the task genuinely requires it. This isn't theoretical — developers are building these pipelines today.
IDC projects global AI spending will climb from roughly 500 billion by 2027. A growing slice of that will flow toward on-premises and edge infrastructure rather than cloud API calls.
The edge AI market is accelerating
The broader edge AI market — of which local inference is a part — is projected to grow at roughly 19% annually, reaching $157 billion by 2030. Consumer operating systems are already moving in this direction: Apple's on-device intelligence features and Google's Gemini Nano integration signal that OS-level local AI is arriving, not speculative.
Smaller, sharper models
The 2025–2026 model landscape has shifted toward smaller, highly efficient models: Phi-4, Gemma 3, and Qwen 3 all deliver strong performance at parameter counts that fit comfortably on consumer hardware. As hardware improves and quantization techniques advance, the gap between "what you can run locally" and "what you'd get from a cloud API" will continue to narrow.
The Real Shift
The genuine story of Ollama isn't technical. It's about who controls the intelligence.
Cloud AI is powerful but carries implicit costs: your data trains their models (sometimes), your budget scales with their pricing, and your operations depend on their uptime. Local AI via Ollama trades some capability ceiling for complete ownership — of the data, the cost structure, and the infrastructure.
For enterprises managing sensitive data, that trade is increasingly worth making. For developers who want to build without per-token costs or data exposure, it already was.
The question for most teams in 2026 isn't whether to explore local AI. It's which workloads belong there.
References
-
RockB (April 2026). Best Ollama Models for Coding 2026: Ranked and Tested. https://baeseokjae.github.io/posts/best-ollama-models-coding-2026/
-
Release Alert (June 2026). Releases · ollama/ollama – GitHub. https://releasealert.dev/github/ollama/ollama
-
GitHub (June 2026). ollama/ollama repository. https://github.com/ollama
-
Wikipedia (2026). Ollama. https://en.wikipedia.org/wiki/Ollama
-
Medium – Ryan (May 2025). A New Perspective on the US-China AI Race: 2025 Ollama Deployment Comparison and Global AI Model Trend Insights. https://medium.com/@realryan/a-new-perspective-on-the-us-china-ai-race-2025-ollama-deployment-comparison-and-global-ai-model-3fc0463590bf
-
Software Tailor Blog (February 2025). Local AI Adoption in Enterprise: Trends and Insights. https://blog.softwaretailor.com/2025/02/local-ai-adoption-in-enterprise-trends.html
-
Software Tailor Blog (March 2025). Cloud AI vs Local AI: Latency, Performance, and Business Impact. https://blog.softwaretailor.com/2025/03/cloud-ai-vs-local-ai-latency.html
-
Edge Industry Review (2025). Edge AI market to hit $157B by 2030, driven by manufacturing and computer vision. Referenced via https://blog.softwaretailor.com/2025/02/local-ai-adoption-in-enterprise-trends.html
-
IDC (via Equinix Blog). Public Cloud vs. Private Cloud for AI — Global AI spending forecast. Referenced via https://blog.softwaretailor.com/2025/02/local-ai-adoption-in-enterprise-trends.html
-
Collabnix (2025). Best Ollama Models in 2025: Complete Performance Comparison. https://collabnix.com/best-ollama-models-in-2025-complete-performance-comparison/